


In the world of cloud computing, where uptime and reliability are paramount, Chaos Engineering has emerged as a powerful methodology for testing the resilience of applications and infrastructure. Amazon Web Services (AWS), being a leading cloud provider, offers a robust platform for implementing Chaos Engineering practices. 40% of businesses will adopt chaos engineering as part of their DevOps initiatives in 2023 according to I&O Leader’s Guide to Chaos Engineering by Gartner. The report also says that chaos engineering reduces unplanned downtime by 20%.
Chaos Engineering is a discipline that focuses on proactively introducing controlled chaos into a system to uncover vulnerabilities, weaknesses, and potential points of failure. It is about embracing failure as a natural part of system operation and learning how to build resilient systems that can withstand unexpected disruptions.
Chaos Engineering provides a method for your teams to gain profound insights into your workloads. It involves conducting controlled chaos experiments, which are rooted in real-world hypotheses. These experiments are precisely scoped to anticipate their impact on the workload and incorporate a rollback mechanism in cases where availability or recovery processes are in place to address failures.
Chaos Engineering fosters operational readiness and encourages the adoption of best practices in how workloads are observed, designed, and implemented to withstand component failures with minimal or no disruption to end users. Consequently, Chaos Engineering can result in enhanced resilience and observability, ultimately elevating the end-user experience and increasing organizational uptime.
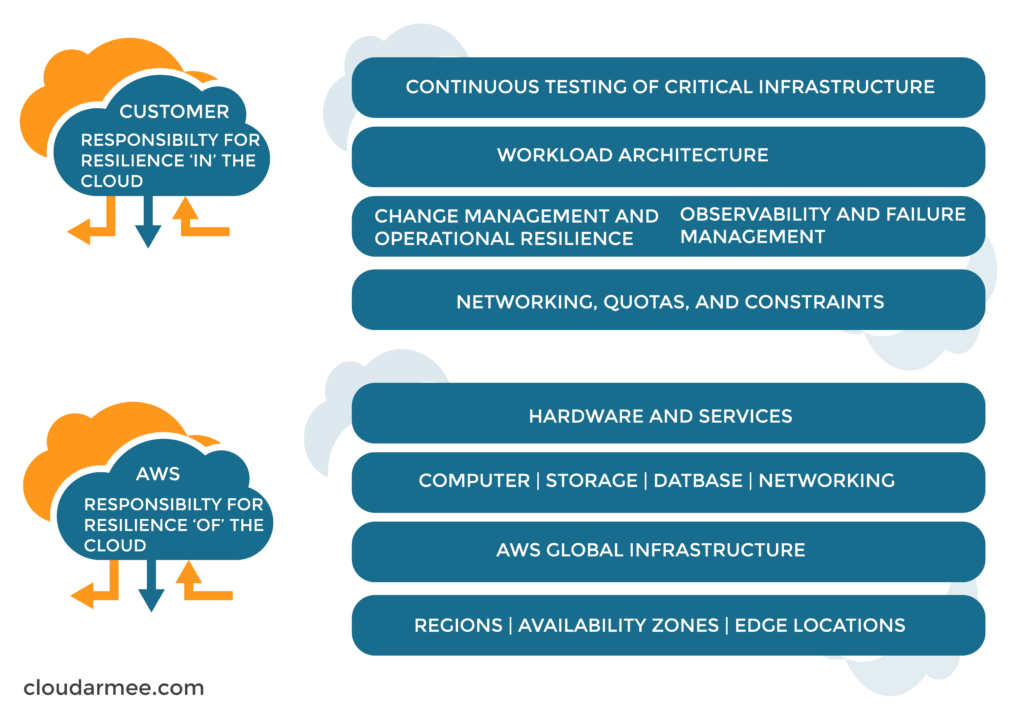
The concept of separating duties presents resilience challenges. These challenges include:
In regulated industries like Finance, Healthcare, and Government, quarterly/yearly disaster-recovery exercises and business continuity plans offer some simulation benefits. However, these planned exercises primarily validate known-state failovers and may not cover all real-world failure scenarios.
Chaos Engineering brings substantial value to your organization by proactively addressing unforeseen disruptions. It accomplishes this by systematically introducing controlled real-world disturbances as part of scheduled activities within your software development lifecycle, continuous integration and continuous delivery (CI/CD) pipelines, and across various levels of cloud infrastructure, workload components, and processes.
It instills the confidence, oversight, and discipline necessary to ensure that experiments do not negatively impact customers. If they do, the experiments can be promptly halted. Through these measures, your teams gain invaluable insights from failures in a controlled setting. They can observe, assess, and enhance the resilience of workloads while confirming the functionality of logs, metrics, and alarms to promptly alert operators within predefined timeframes.
AWS provides a wide range of services and tools that facilitate Chaos Engineering experiments, making it an ideal platform for testing resilience in the cloud. Here’s how AWS supports Chaos Engineering:
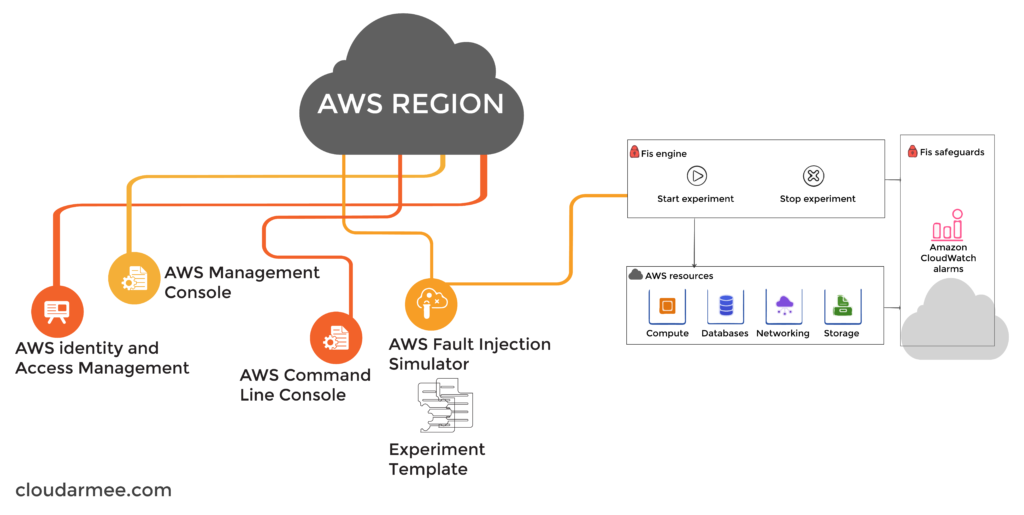
Chaos Engineering is a critical practice for enhancing the resilience of your AWS DevOps environment. By deliberately introducing controlled chaos into your systems and leveraging AWS’s robust tools and services, you can identify weaknesses and vulnerabilities, ultimately ensuring that your applications are better equipped to withstand real-world disruptions in the cloud. Embrace Chaos Engineering as a proactive strategy for building more reliable and resilient systems on AWS.
CloudArmee is your strategic cloud partner. We help you drive business growth and transformation. Our 4Ops framework helps you lower the cost of managing IT infrastructure through improved productivity and operational efficiency.